Introdução
Esse roteiro é fruto de um grupo de discussões sobre modelos mistos da LAGE (IB - USP), escrito por mim, Marília Gaiarsa e Lucas Medeiros. O nosso objetivo é apresentar modelos lineares mistos e a sua aplicação usando dados ecológicos e o ambiente de programação R1.
Nesse momento, você deve estar se perguntando: esse roteiro é para mim?! Para acompanhá-lo é interessante ter uma compreensão básica de análises estatísticas em R. Isso quer dizer que você já usou e sabe interpretar o output de funções como lm(). Esperamos que ao terminar você seja capaz de:
Entender o que são efeitos fixos e aleatórios.
Compreender a estrutura básica de um modelo linear misto.
Fazer uma análise de modelo misto no R usando o pacote
lme4(Bates et al. 2014)Entender o output da função
lmer.Decidir quais efeitos aleatórios manter no seu modelo final.
Tirar conclusões a partir da análise de um modelo misto por meio de teste de hipótese ou seleção de modelos.
Fazer uma análise visual de diagnóstico do modelo.
Caso se sinta um pouco perdido com certas terminologias estatísticas ou queira relembrar alguns termos, ao final do roteiro temos um pequeno glossário que pode ajudar.
Modelos Mistos
Para explicar o que são modelos mistos e sua importância em ecologia, usaremos como exemplo um conjunto de dados presente no capítulo 5 de Zuur et al. (2009). Esses dados contêm a riqueza de espécies da macro-fauna em 9 praias na costa da Holanda. Em cada uma das praias, os autores coletaram dados em cinco sítios diferentes. Para cada sítio existe informação sobre a altura da estação de amostragem em relação à altura média da maré (NAP). Vamos supor que estamos interessados em verificar se a variável NAP influencia a riqueza de espécies nessas praias. Uma primeira ideia que poderíamos ter é construir um modelo linear da seguinte forma:
\[riqueza = \alpha + \beta * NAP + \varepsilon\]
Aqui estamos modelando a riqueza de cada praia em função da variável NAP. O coeficiente \(\alpha\) é o intercepto do modelo, \(\beta\) é o coeficiente angular (inclinação) de NAP e \(\varepsilon\) é o erro do nosso modelo (resíduos), isto é, a variação da riqueza que não conseguimos explicar com nossa variável preditora NAP. No entanto, esse modelo tem um problema. Estamos violando uma premissa fundamental de modelos lineares, a de que os dados são independentes uns dos outros (Winter, 2013). Os dados obtidos em uma mesma praia não são independentes entre si (dependência espacial). Podemos imaginar diversas características de cada praia que podem influenciar a riqueza de espécies, como o tipo de grão de areia ou a força das ondas. Veja o gráfico abaixo2, em que cada cor representa uma praia, para se convencer de que a relação entre riqueza e NAP varia entre praias:
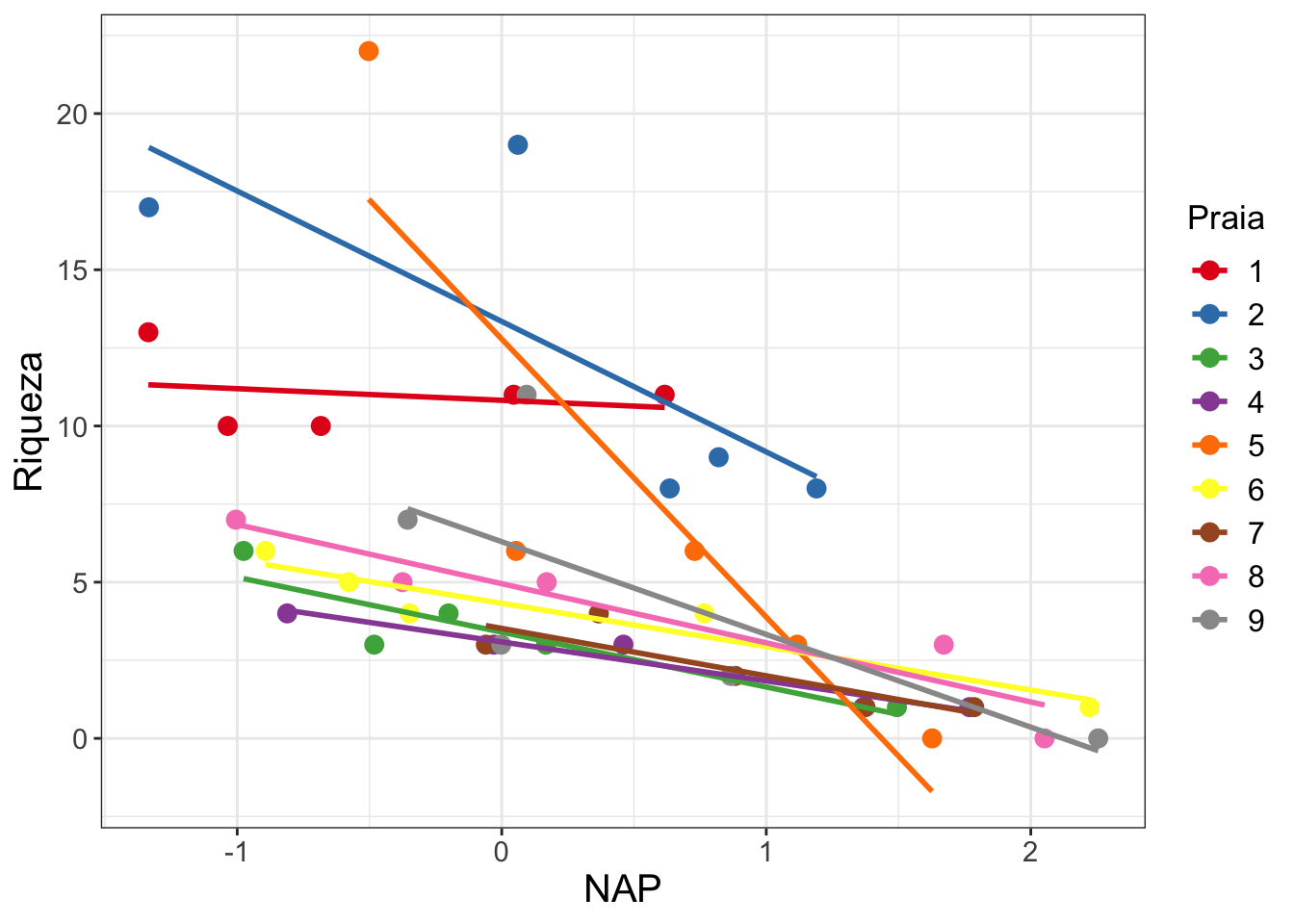
Figure 1: Relação entre riqueza e NAP para cada ponto em cada praia amostrada. As linhas retas representam a reta do modelo ajustado para cada praia separadamente.
Nesta figura, temos as retas do modelo entre Riqueza e NAP aplicado para cada praia (usando a função lm()). Entretanto, nossa pergunta inicial não diz respeito a cada praia separadamente, nós queremos modelar esta relação para todas as praias amostradas, sem pseudoreplicação (não-independência dos dados) e queremos fazer isso de forma a ser possível predizer a riqueza em praias não amostradas.
Portanto, precisamos de um modelo linear que incorpore o fato de que nossos dados estão agrupados em praias. Chamamos de um efeito aleatório uma variável que agrupa nossos dados e que seu efeito sobre a variável resposta não nos interessa diretamente (nesse exemplo não interessa, mas dependendo da análise, pode interessar - veja discussão em McGill 2015). Nesse caso, os autores amostraram nestas 9 praias, mas poderiam ter feito o mesmo estudo escolhendo outras praias. O efeito aleatório praia “organiza” a parte da variação nos nossos dados que não conseguimos explicar, presente no erro \(\varepsilon\) do modelo (Winter, 2013). Por outro lado, as variáveis preditoras que estamos acostumados a encontrar em modelos lineares são chamadas de efeitos fixos. No exemplo das praias, a variável NAP é um efeito fixo e estamos diretamente interessados em seu efeito sobre a variável resposta. O nome “misto” advém do fato de que existe ao menos um efeito fixo e um efeito aleatório.
Em ecologia, é comum encontrarmos delineamentos amostrais ou experimentais que geram dados com algum tipo de agrupamento (delineamento hierárquico ou aninhado). Por exemplo, quando uma amostragem é feita por parcelas ou quando um experimento é separado em diferentes blocos. Nesses casos, não podemos tratar nossos dados como independentes e a abordagem estatística mais adequada é a de modelos mistos.
Na seção a seguir veremos como explorar modelos mistos no R. Veremos que a forma mais simples de incorporar o efeito aleatório em nosso exemplo é definir que cada praia apresenta um intercepto diferente no modelo. Ou seja, queremos ajustar uma reta para nossa relação entre riqueza e NAP, mas permitir que cada praia tenha sua própria “retinha”, com intercepto variando em relação ao intercepto da reta “principal” (efeito fixo). Nosso modelo será:
\[riqueza_i = \alpha + b_i + \beta * NAP + \varepsilon_{i}\]
A riqueza da praia i é explicada pelo efeito fixo \(\beta*NAP\) e pelo efeito aleatório \(b_i\), que se soma ao valor do intercepto fixo do modelo, \(\alpha\), para formar o intercepto da praia i. Veja que o índice i está atrelado a \(b_i\) e, portanto, o modelo permite que cada uma das praias apresente uma relação diferente entre riqueza e NAP. Já \(\beta\) faz parte do efeito fixo, e não possuí nenhum índice i atrelado a ele. Finalmente, \(\varepsilon\) representa o erro associado a cada uma das amostras na mesma praia.
Mãos à massa! Modelos mistos no R
Existem vários pacotes disponíveis no R para realizar análises de modelos mistos. Neste roteiro usaremos o lme4 (Bates et al. 2014), que possui funções para analisar modelos lineares mistos, modelos lineares mistos generalizados e modelos mistos não lineares. A seguir, vamos colocar a mão na massa e analisar os dados provenientes do capítulo 5 de Zuur et al. (2009) que exploramos na seção anterior.
Antes de tudo, precisamos baixar e instalar o pacote lme4:
install.packages("lme4")
library(lme4)Os dados estão disponíveis no site do livro do Zuur et al. (2009) (baixe aqui o zip com os dados - “data files”).
dados <- read.table("RIKZ.txt", header = TRUE, row.names = 1, as.is = TRUE)Nossa tabela de dados não possui nenhum valor faltante, mas caso possuísse, não tem muito problema em análises de modelos mistos. Agora, vamos construir nosso modelo.
| Richness | Exposure | NAP | Beach | Praia |
|---|---|---|---|---|
| 11 | 10 | 0.045 | 1 | 1 |
| 10 | 10 | -1.036 | 1 | 1 |
| 13 | 10 | -1.336 | 1 | 1 |
| 11 | 10 | 0.616 | 1 | 1 |
| 10 | 10 | -0.684 | 1 | 1 |
| 8 | 8 | 1.190 | 2 | 2 |
| 9 | 8 | 0.820 | 2 | 2 |
| 8 | 8 | 0.635 | 2 | 2 |
| 19 | 8 | 0.061 | 2 | 2 |
| 17 | 8 | -1.334 | 2 | 2 |
Relembrando, estamos interessados em ver se existe um efeito de NAP na riqueza de espécies. Nossos dados contam com nove diferentes praias e cinco diferentes amostras para cada uma delas. Dessa forma, temos como efeito fixo a variável NAP, e como efeito aleatório a variável praia (Beach), que significa que cada praia terá um intercepto diferente. Assim, nosso modelo é:
modelo.riqueza <- lmer(Richness ~ NAP + (1 | Beach), data = dados)Em seguida, vamos dar uma olhada no output do modelo:
summary(modelo.riqueza)## Linear mixed model fit by REML ['lmerMod']
## Formula: Richness ~ NAP + (1 | Beach)
## Data: dados
##
## REML criterion at convergence: 239.5
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -1.4227 -0.4848 -0.1576 0.2519 3.9794
##
## Random effects:
## Groups Name Variance Std.Dev.
## Beach (Intercept) 8.668 2.944
## Residual 9.362 3.060
## Number of obs: 45, groups: Beach, 9
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 6.5819 1.0958 6.007
## NAP -2.5684 0.4947 -5.192
##
## Correlation of Fixed Effects:
## (Intr)
## NAP -0.157Vamos dar uma olhada na parte dos efeitos aleatórios. O desvio padrão é uma medida do quanto a variablidade da nossa variável dependente - riqueza - é devida aos dois efeitos aleatórios que estamos analisando (os interceptos das praias e os resíduos). Podemos ver o desvio padrão associado às diferenças de intercepto entre praias (o \(b_i\) do modelo). A última linha nos dá o resíduo, que indica o quanto da variabilidade não é prevista pela praia nem pelo NAP, que nada mais é do que o \(\varepsilon\) acima explicado.
Os efeitos fixos indicam os coeficientes estimado pra cada um dos fatores que estamos considerando como fixos. No caso, temos o intercepto que é a riqueza quando o NAP é zero (6.5818929), e o coeficiente angular de NAP (-2.5683996).
#criando objeto com os coeficientes do modelo (efeitos fixos)
cof <- fixef(modelo.riqueza)Para fazer o gráfico de nosso modelo ajustado, com a reta (predição) dos efeitos fixos e as “retinhas” preditas para cada praia, vamos primeiro calcular os valores preditos para cada praia3.
# Primeiro criamos um novo conjunto de dados com as características no antigo
novo <- expand.grid(Beach = unique(dados$Beach),
NAP = seq(-1.3,2.2,0.5))
#agora calculamos os valores preditos para esse novo conjunto de dados
preditos <- predict(modelo.riqueza, newdata = novo)
#guardando tudo em um novo data.frame
dados.preditos <- data.frame(pred = preditos, novo)Agora podemos plotar os dados com o ajuste do nosso modelo4:
library(ggplot2)
funi <- function(x){cof[1] + cof[2]*x} # para plotar a predição dos efeitos fixos
dados$Praia = as.factor(dados$Beach)# transformando praia em fator
ggplot(data = dados, aes(x = NAP, y = Richness, color = Praia)) + # dados e eixos
geom_point(size = 3, shape = 19) + # plotando os pontos das praias
geom_line(data = dados.preditos, aes(y = pred, x = NAP,
col = as.factor(Beach))) + # retas de cada praia
stat_function(fun = funi, col = "black", size = 2) + # reta do modelo fixo
scale_color_brewer(palette = "Set1") + # a partir daqui estética do gráfico
theme_bw() +
theme(axis.text = element_text(size = 13),
axis.title = element_text(size = 15),
axis.text.x = element_text(size = 11),
axis.text.y = element_text(size = 11),
legend.key.size = unit(0.6, "cm"),
legend.text = element_text(size = 12),
legend.title = element_text(size = 13)) +
xlab("NAP") +
ylab("Riqueza")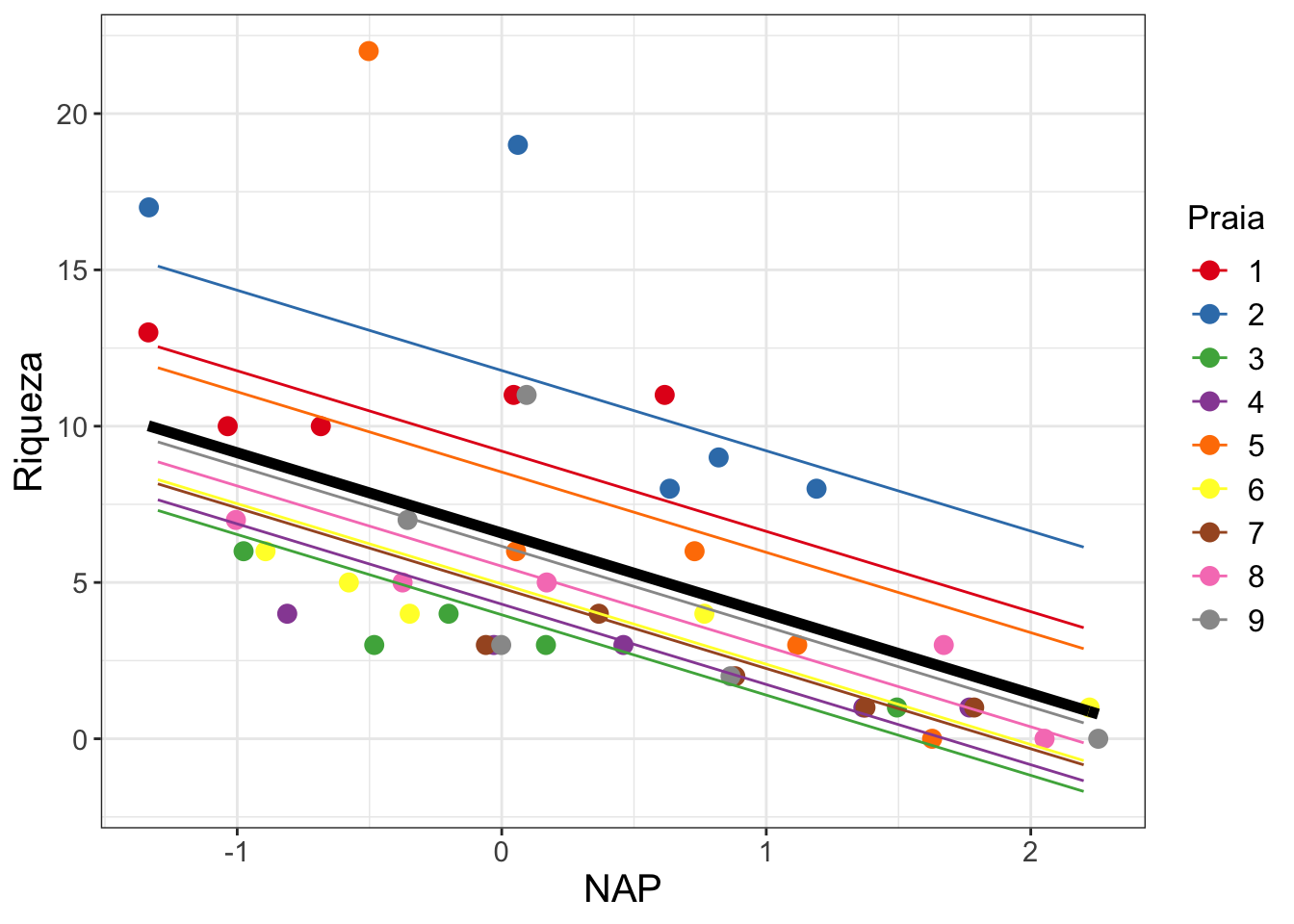
Figure 2: Gráfico do ajuste do modelo com a reta em preto sendo o predito pelos modelos fixos e as retas coloridas as predições para cada praia.
Podemos ver nessa figura a predição do nosso modelo em relação aos parâmetros fixos (reta em preto), e as predições para cada praia separadamente. Como o efeito aleatório do nosso modelo estava apenas variando os valores de intercepto das praias, as retas para cada praia são paralelas.
Existem, entretanto, diversas maneiras de criar seu modelo, escolher os parâmetros importantes, e decidir quais são fixos e quais são aleatórios. Nesse exemplo, poderíamos colocar a variável Exposure também como um efeito fixo (mais indicado seria usá-la como um fator com 3 níveis). Outra complicação que poderíamos inserir no nosso modelo é inserir mais um efeito aleatório de interação entre a praia (efeito aleatório) e NAP (efeito fixo), fazendo com que cada praia possa ter inclinações de reta diferentes.
Por isso, é importante testar diferentes modelos antes de decidir qual é o melhor. Na próxima parte abordaremos como selecionar o melhor modelo dadas todas as possibilidades.
Escolha dos efeitos aleatórios
Existem modelos e, portanto, perguntas e delineamentos amostrais, que requere apenas um efeito aleatório para indicar o agrupamento dos dados. Entretanto, como colocado no final da seção anterior, há também modelos que podem incluir mais de um efeito aleatório. Esse é o caso da interação entre praia e NAP mencionada acima. Se olharmos para a primeira, veremos que cada praia parece ter seu próprio intercepto e inclinação, o que torna plausível pensarmos que o modelo com a interação se ajuste melhor aos nosso dados.
Para modelos que podem ter mais de um efeito aleatório, Zuur et al. (2009), sugere um protocolo para a escolha da melhor estrutura de efeitos aleatórios. Vamos aos passos:
- A primeira coisa a ser feita é ajustar um modelo com todos os efeitos fixos que estão sendo testados (modelo “completo”). No nosso exemplo tínhamos apenas
NAP, mas vamos incluirExposure(como fator) para exemplificar melhor, e vamos incluir a interação entreNAPeExposure. Nosso modelo “completo” é:
Richness ~ Exposure * NAP + efeito(s) aleatório(s)- Depois que escolhemos o modelo “completo”, adicionamos com os efeitos aleatórios plausíveis. No nosso exemplo, escolhemos duas possibilidades de efeito aleatório, variações no intercepto entre praias (
(1|Beach)) e a interação entre praia e NAP, resultando também na variação de inclinação entre praias ((NAP|Beach)). Podemos também ajustar um modelo sem efeito aleatório (usando a funçãolm) e ver se a inclusão do efeito aleatório resulta num melhor ajuste do modelo:
# os modelos possíveis do nosso exemplo
m0 <- lm(Richness ~ as.factor(Exposure) * NAP, data = dados) #sem efeito aleat.
m1 <- lmer(Richness ~ as.factor(Exposure) * NAP + (1|Beach), data = dados)
m2 <- lmer(Richness ~ as.factor(Exposure) * NAP + (NAP|Beach), data = dados)Um ponto importante é que estes modelos serão ajustados utilizando uma forma diferente de estimação, ao invés da máxima verossimilhança (ML), vamos usar a máxima verossimilhança restrita (REML). Isso acontece porque a ML é enviesado para as estimativas de variância do modelo e a REML corrige este enviesamento. Na prática, nós não precisamos fazer nada, pois a função lmer já usa, por padrão, a REML (argumento REML = T).
- Colocamos estes modelos ajustados para “concorrer” usando o Critério de Informação de Akaike (AIC), como um critério para a seleção de modelos (menor AIC, melhor modelo) (ver Burnham & Anderson 2002). Como temos poucos dados vamos usar o AICc - que é uma correção do AIC para pequeno tamanho amostral.
# usamos a função AICctab do pacote bbmle
library(bbmle)
AICctab(m0, m1,m2, base = T, weights = T)## AICc dAICc df weight
## m1 231.3 0.0 8 0.729
## m2 233.6 2.3 10 0.234
## m0 237.3 5.9 7 0.037Bom, agora sabemos que a melhor estrutura de efeito aleatório é apenas a varição no intercepto entre as praias. Assim, podemos prosseguir com a verificação dos efeitos fixos através de teste de hipóteses e/ou seleção de modelos.
Inferência e diagnóstico do modelo
Nessa parte, depois de já escolhermos a estrutura aleatória do nosso modelo, podemos averiguar qual a real influência dos efeitos fixos na riqueza de espécies. Vou apresentar duas abordagens de inferência, o Teste de Hipóteses através da comparação de modelos por ANOVA (que também é uma seleção de modelos) e a seleção de modelos por AIC. E, depois de selecionado o modelo que melhor se ajusta aos dados, vamos fazer o diagnóstico dos resíduos deste modelo para ver se ele atende às premissas de um modelo linear misto.
Teste de hipótese
Você pode perceber que o output da função lmer não dá as estatísticas t e o valor de P, dos parâmetros fixos do modelo como faz um lm (veja o summary do nosso primeiro modelo e compare com o m0). Isso porque a chamada “estatística Wald” não é recomendada para modelos mistos (sobre isso melhor olhar nas referências recomendadas). O que se faz para saber se uma variável é significativa ou não é construir modelos aninhados (ou seja, retirando um parâmetro do modelo com mais parâmetros) e comparando por uma Análise de Variãncia (ANOVA).
Nesse caso, precisamos ajustar nosso modelo por máxima verossimilhança (ML), pois é o indicado para compararmos modelos com diferentes efeitos fixos mas com mesmo efeito aleatório. Então colocamos o argumento REML = F no nosso modelo:
# modelo com interação entre Exposure e NAP
m1 <- lmer(Richness ~ as.factor(Exposure) * NAP + (1|Beach), data = dados, REML = F)
# modelo sem interação entre exposure e NAP
m3 <- lmer(Richness ~ as.factor(Exposure) + NAP + (1|Beach), data = dados, REML = F)E aplicamos a função anova nos nossos modelos aninhados:
anova(m1,m3)## Data: dados
## Models:
## m3: Richness ~ as.factor(Exposure) + NAP + (1 | Beach)
## m1: Richness ~ as.factor(Exposure) * NAP + (1 | Beach)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## m3 6 238.31 249.15 -113.16 226.31
## m1 8 236.26 250.71 -110.13 220.26 6.0524 2 0.0485 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Como o resultado da comparaçaõ entre os modelos foi significativo, nós paramos por aqui, ou seja, o modelo com interação é significativamente diferente do modelo sem interação. O que podemos fazer é assegurar que o modelo com interação é também diferente do modelo nulo (sem efeitos fixos):
# modelo nulo
m6 <- lmer(Richness ~ 1 + (1|Beach), data = dados, REML = F)
anova(m1,m6)## Data: dados
## Models:
## m6: Richness ~ 1 + (1 | Beach)
## m1: Richness ~ as.factor(Exposure) * NAP + (1 | Beach)
## npar AIC BIC logLik deviance Chisq Df Pr(>Chisq)
## m6 3 269.30 274.72 -131.65 263.30
## m1 8 236.26 250.71 -110.13 220.26 43.042 5 3.623e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Sim. Então podemos concluir que tanto Exposure quanto NAP influenciam na riqueza de espécies. Caso não tivesse havido diferença entre o modelo com interação e sem, nós deveríamos prosseguir com a seleção de modelos fazendo a comparação entre o modelo com as duas variáveis e modelos com cada variável separadamente.
Seleção de modelos por AICc
Uma outra forma de analisar os dados seria fazer de uma vez só uma seleção de modelos usando a abordagem de seleção de modelos por AIC (AICc no nosso caso). Essa forma de analisar é parecida com o que foi utilizado para escolha do efeito aleatório, porém neste caso estamos comparando modelos com diferentes efeitos fixos mas com meso efeito aleatório. Então vamos usar também REML = F em todos os modelos:
m1 <- lmer(Richness ~ as.factor(Exposure) * NAP + (1|Beach), data = dados, REML = F)
m3 <- lmer(Richness ~ as.factor(Exposure) + NAP + (1|Beach), data = dados, REML = F)
m4 <- lmer(Richness ~ as.factor(Exposure) + (1|Beach), data = dados, REML = F)
m5 <- lmer(Richness ~ NAP + (1|Beach), data = dados, REML = F)
m6 <- lmer(Richness ~ 1 + (1|Beach), data = dados, REML = F)AICctab(m1,m3,m4,m5,m6, base = T, weights = T)## AICc dAICc df weight
## m1 240.3 0.0 8 0.5314
## m3 240.5 0.3 6 0.4659
## m5 250.8 10.6 4 0.0027
## m4 264.1 23.8 5 <0.001
## m6 269.9 29.6 3 <0.001Usando essa abordagem, vemos que o modelo com interação entre NAP e Exposure é o melhor, porém ele é igualmente plausível ao modelo sem interação (usamos \(\delta AICc < 2\) como modelos igualmente plausíveis). Nesse ponto, as duas abordagem diferiram, mas se olharmos bem para o valor de P do teste entre os modelos com e sem interação (0,0485) vemos que eles está no “limiar de significância”, ou seja, é quase 0,05.
Independente da abordagem que usamos (poderíamos também ter ajustado um modelo bayesiano - mas daí é tópico para outro roteiro), precisamos, depois de “escolhido” o modelo que melhor se ajusta aos nossos dados, avaliar este ajuste e as premissas deste modelo.
Diagnósticos dos modelos
O primeiro diagnóstico do modelo é verificar se os resíduos são normalmente distribuídos, para isso geralmente usamos um qqplot (gráfico de quantil-quantil da distribuição normal) e possivelmente um teste de normalidade (por exemplo o Shapiro-Wilks). Além disso podemos também checar visualmente a homogeneidade de variância dos resíduos (homocedasticidade), ou seja, se a variablidade dos resíduos se mantém constante em relação aos valores ajustados.
Para isso usamos a função plotresid do pacote RVAidememoire:
library(RVAideMemoire)
plotresid(m1, shapiro = T)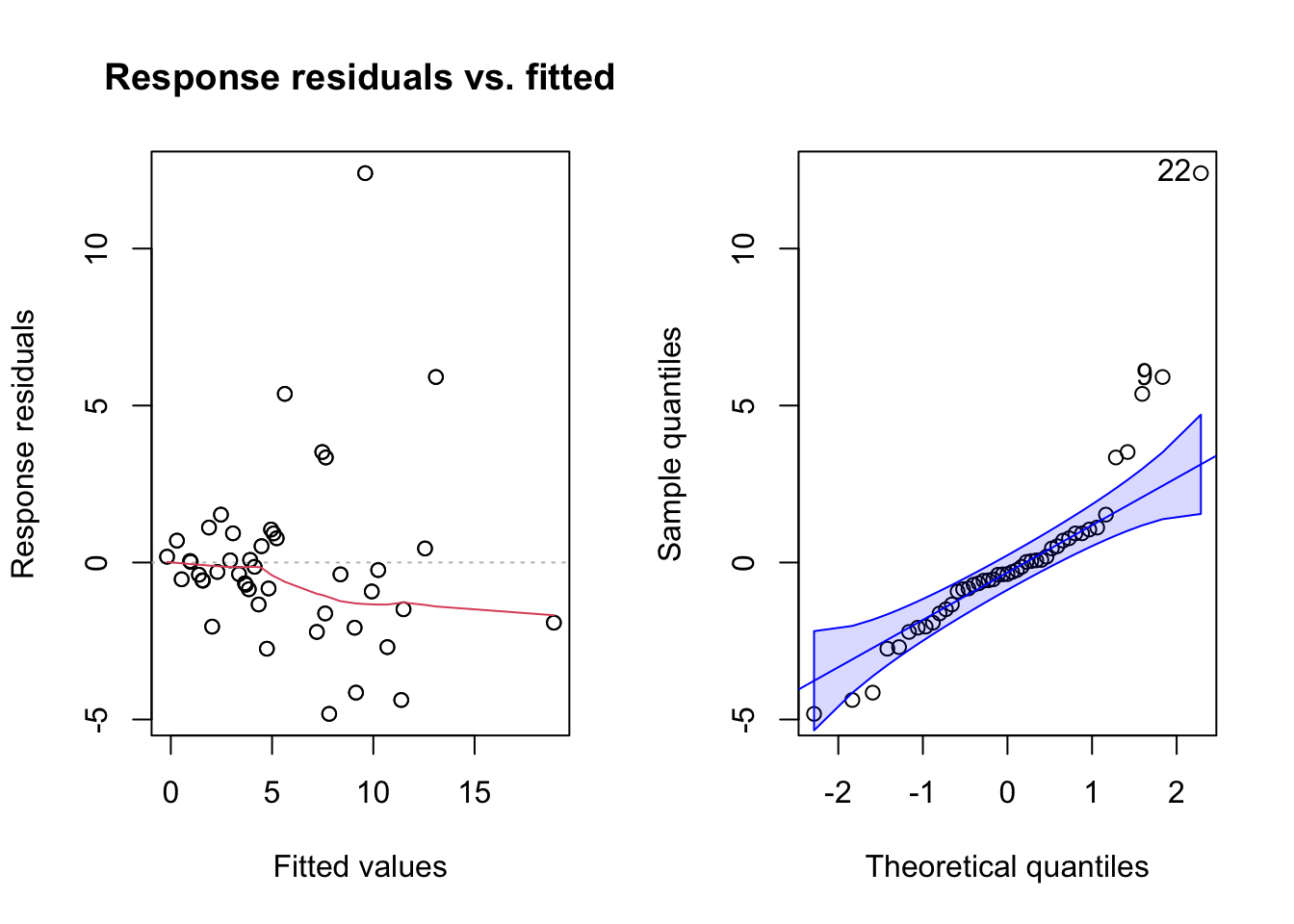
Figure 3: Gráficos de resíduos do melhor modelo ajustado.
##
## Shapiro-Wilk normality test
##
## data: model.res
## W = 0.81589, p-value = 5.416e-06OPS! Olhando o gráfico da esquerda, vemos que os dados não são tão homocedásticos como gostaríamos, vemos algo parcido com um funil se abrindo da esquerda para a direita, o que indica que estamos violando esta premissa. Olhando o gráfico da direita (o qqplot), temos que os valores extremos dos dados não se comportam muito bem como uma distribuição normal (as linhas em vermelho no gráfico indicam a área em que os pontos deveriam estar para que pudéssemos considerar os resíduos como normalmente distribuídos). Isso fica evidente quando fazemos o teste de Shapiro e encontramos que os dados são significativamente diferentes de uma distribuição normal (nesse teste se dá significativo é que não é normal).
E agora??! Bem, não estamos totalmente perdidos, existe um caminho! O problema foi que nós assumimos que a riqueza de espécies poderiam ser modelados como pertencentes a uma distribuição normal. Entretanto, dados de contagem (nesse caso, número de espécies) são geralmente modelados usando a distribuição de Poisson, que também leva em consideração que a média é igual à variância.
Então, para fazermos a modelagem correta dos nossos dados teremos que usar um modelo com distribuição de Poisson, que está implementado no pacote lme4 com a função glmer.
Mas isso é tema para outro roteiro…
Se você se interessou pelos modelos mistos e acha que eles se encaixamo no seu problema, não deixe de conferir as referências que a gente listou abaixo para se aprofundar nesse universo!!
Glossário
Efeitos fixos e aleatórios
Existe muita discussão na literatura sobre como se diferencia efeitos fixos de aleatórios (veja sugestões de leitura no final do roteiro). De maneira geral, efeitos fixos são constantes em toda sua amostra, não variam de amostra pra amostra. Além disso, os diferentes níves existentes no efeitos fixos não variam se você incluir mais amostras (Bates et al 2014). Um exemplo claro é sexo: normalmente sua amostra conterá machos e fêmeas, e aumentar o seu n amostral a quantidade de níveis em seus fatores permanecerá constante.
Máxima verossimilhança
Máxima verossimilhança (ML) é uma abordagem estatística que estima os parâmetros de um modelo a partir de um dado conjunto de dados.
Nos modelos mistos normais (que assume distribuição normal dos resíduos), utiliza-se a máxima verossimilhança restrita (REML) para estimar os parâmetros, pois a ML enviesa as estimativas de variância do modelo.
Modelo linear
Modelos lineares descrevem a resposta de uma variável dependente, a que você está interessado em explorar, em função de uma variável preditora, explanatória ou independente.
\[dependente \sim preditora \]
Em ecologia, um dos usos mais comuns de modelos lineares se dá quando realizamos regressões ou correlações, por exemplo. Para fazer um modelo linear no R normalmente usamos a função lm:
lm (dependente ~ preditora, data = seus dados)Modelo aninhado
É o tipo de modelo que utilizamos modelos mistos, no qual um modelo mais geral está aninhado dentro de outros modelos de modo que as variáveis independentes do modelo mais especíico formam um subconjunto das variáveis do modelo mais geral. No exemplo das praias isso é facilmente visualizado dado que dataset é composto de nove praias, e para cada uma das nove praias existem cinco amostras. O modelo linear não considera esse aninhamento dos dados e o fato de que, muito provavelmente, a riqueza em cada uma das cinco amostras está muito mais relacionada entre si do que entre praias.
Referências e recomendações
Bates, et al. 2014..Fitting linear mixed-effects models using lme4. arXiv preprint arXiv:1406.5823. (publicação do pacote lme4)
Burnham, K. & Anderson, D. 2002. Model selection and multimodel inference: a practical information-theoretic approach. 2nd edn. New York: Springer-Verlag. (Livro sobre a abordagem de seleção de modelos baseada em Teoria da Informação)
McGill, B. 2015. Is it a fixed or random effect? Blog Dynamic Ecology. (Uma boa discussão sobre o que são efeitos fixos e aleatórios)
Winter, B. 2013. Linear models and linear mixed effects models in R with linguistic applications. arXiv:1308.5499. (Nesse excelente roteiro, o autor explica modelos lineares e depois apresenta modelos mistos de uma forma bem didática)
Zuur, A., Ieno, E., Walker, N., Saveliev, A. & Smith, G. 2009. Mixed effects models and extensions in ecology with R. (Livro muito bom e completo sobre modelos mistos e aditivos)
caso queira ter acesso ao arquivo .Rmd do roteiro acesse o repositório no github.↩︎
clique no gráfico para ver em maior tamanho.↩︎
esse valor predito é o que se considera naive, quando não estamos incorporando a variabilidade dos efeitos aletórios. Como introdução é válido calcular os valores preditos desta maneira, mas para se aprofundar no tema sugerimos ler Bates et al. (2014) para formas mais apropridades de predição.↩︎
estamos usando o pacote
ggplot2para fazer o gráfico↩︎